pwn-笔记
pwn-学习笔记
啥几把不会
传上来充数
————————————————————————-
mfc
一般用xspy打开,找偏移,然后看文件基址锁定文件主函数
d180
一般是去除ollvm(快捷键ctrl+shift+D)

反调试-PEB
readfsdword 是一个与低级操作系统和汇编相关的函数,它通常用于从 FS 段寄存器指定的内存地址读取数据。在 x86 和 x64 架构中,FS 是一个段寄存器,它可以用来访问线程局部存储(TLS)和其他特定于操作系统的数据结构。
1 | mov eax, fs:[0x30] ; 从 FS 段寄存器的地址 0x30 读取一个双字(32 位) |
isDebuggerPresent 函数

————————————————————————–
可见字符串
1 | !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ |
mips

首先在csdn上了解了一下pwn
什么是二进制漏洞
二进制漏洞是可执行文件(PE、ELF文件等)因编码时考虑不周,造成的软件执行了非预期的功能。由于二进制漏洞大都涉及到系统层面,所以危害程度比较高。比如经典的office栈溢出漏洞(CVE-2012-0158)、(CVE-2017-11882)以及(CVE-2017-11882)的补丁绕过漏洞(CVE-2018-0802)等,都是危险程度极高的0day和1day漏洞。所以,二进制漏洞的挖掘和分析就显得尤为重要,本篇文章将对常见的二进制漏洞进行简要的介绍和分析。
认识到常见的二进制漏洞
栈溢出漏洞、堆溢出漏洞、释放后重引用漏洞、双重释放漏洞、越界访问漏洞。
模块全部如下:

pe结构




0xdeadbeef 是一个常见的“魔数”(magic number),经常被用作调试和错误检测中的哨兵值。




IP
1 | sudo dhclient ens33 |

保护机制
Arch:
程序架构信息。判断是拖进64位IDA还是32位?exp编写时p64还是p32函数?
32位一般同过堆栈传参,而64位为通过寄存器传参
RELRO
Relocation Read-Only (RELRO) 此项技术主要针对 GOT 改写的攻击方式。它分为两种,Partial RELRO 和 Full RELRO。
部分RELRO 易受到攻击,例如攻击者可以atoi.got为system.plt,进而输入/bin/sh\x00获得shell
完全RELRO 使整个 GOT 只读,从而无法被覆盖,但这样会大大增加程序的启动时间,因为程序在启动之前需要解析所有的符号。
1 | gcc -o stack stack.c // 默认情况下,是Partial RELRO |
Stack-canary
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让shellcode能够得到执行。当启用栈保护后,函数开始执行的时候会先往栈里插入类似cookie的信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为canary。
1 | gcc -fno-stack-protector -o stack stack.c //禁用栈保护 |
NX
NX enabled如果这个保护开启就是意味着栈中数据没有执行权限,如此一来, 当攻击者在堆栈上部署自己的 shellcode 并触发时, 只会直接造成程序的崩溃,但是可以利用rop这种方法绕过
1 | gcc -o stack stack.c // 默认情况下,开启NX保护 |
PIE
PIE(Position-Independent Executable, 位置无关可执行文件)技术与 ASLR 技术类似,ASLR 将程序运行时的堆栈以及共享库的加载地址随机化, 而 PIE 技术则在编译时将程序编译为位置无关, 即程序运行时各个段(如代码段等)加载的虚拟地址也是在装载时才确定。这就意味着, 在 PIE 和 ASLR 同时开启的情况下, 攻击者将对程序的内存布局一无所知, 传统的改写
GOT 表项的方法也难以进行, 因为攻击者不能获得程序的.got 段的虚地址。
若开启一般需在攻击时泄露地址信息
1 | gcc -o stack stack.c // 默认情况下,不开启PIE |
1 | 把它们四个都关了 |
—————————–
docker
1 | docker tag <镜像ID> <仓库名>:<标签> |
—————————————————————-
查看 .eh_frame 段
1 | readelf --section-headers your_binary | grep .eh_frame |
—————————————————————-
栈溢出的几种利用方法
后门函数(Backdoor)
- 首先找到可以存在溢出漏洞的函数,像:gets、scanf、vscanf、sprintf、strcpy、strcat、bcopy
这里目前我遇到的最多的是gets,还有一个是给定数组长度,但是在函数调用时,所给定的长度远大于给定数组的长度。
- 确定填充的长度,主要是我们要操作的地址与我们要覆盖的地址的距离。
这里最常见的就是用ida查看栈基地址,直接查看而ebp的相对偏移,覆盖需求的话,面前只会覆盖返回地址,和覆盖栈上某个变量的内容。
- 注入后门函数,通过溢出覆盖返回地址,指向我们的后门函数,得到我们的结果
最常见的就是system(/bin/sh)
目前遇见的存在溢出漏洞的函数:
gets函数,最简单的溢出漏洞,ida看一下栈的结构,加上它的ebp(常见的64位为8位,32位为4位),后面就是根据它的溢出点而定。
read函数,题目:BUUCTF-bjdctf_2020_babystack2和jarvisoj_level0,一方面是看他要读取的长度来定看看能不能直接溢出,另一方面根据它的读取错误返回-1来进行溢出,这里就要向远程连接的服务器发送数据来进行溢出。
**栈迁移(劫持)**: 当溢出长度不够时,题目:ciscn_2019_es_2。
思路:将rop链写到栈上,在将栈劫持到我们写的地方。首先泄露出来一个地址然后在计算偏移来确认我们需要劫持的地址
- 所以我们可以先将exploit先这样写出来, leave;ret;指令可以在IDA中找,也可以用ROPgadget查找。其实我们是执行了两次 leave;ret;一次是函数结束时自己调用的一次是我们设置的返回地址,第一次主要是leave指令目的是改变ebp的值,第二次目的是ret指令,执行我们劫持到的地址。
64位程序调用
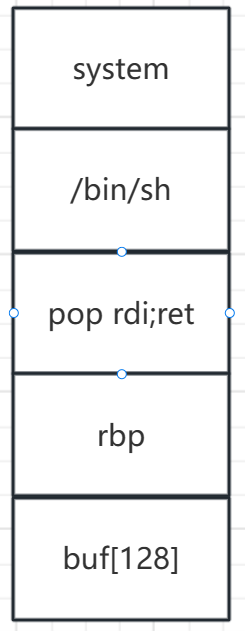
遇见stack保护开启
ROP
栈溢出 ROP(Return-Oriented Programming)是一种利用栈溢出漏洞来执行攻击者控制的代码的技术。它通过利用程序中已存在的代码片段(称为 gadgets),并利用这些 gadgets 的特性来构建一个攻击链,从而达到执行攻击者想要的操作的目的。这种技术是在现代操作系统中常见的漏洞利用方法之一。
- ROP就是使用返回指令ret连接代码的一种技术,而ret指令的本质是pop eip,即把当前栈顶的内容作为内存地址进行跳转。
目前遇见的就是利用ROPgadget工具查看rdi寄存器的地址。
SROP
signal机制
它是unix系统中进程之间相互传递信息的一种方法。(软中断信号或软中断)
进程之间可以通过系统调用kill来发送软中断信号。
① 内核向某个进程发送signal机制,该进程会被暂时挂起,进入内核态
② 内核会为该进程保存相应的上下文,跳转到之前注册好的signal handler中处理signal
③ signal返回
④ 内核为进程恢复之前保留的上下文,恢复进程的执行

- 内核在保存进程相应上下文阶段主要是将所有寄存器压入栈中,以及压入 signal 信息,以及指向 sigreturn 的系统调用地址。此时栈的结构如下图所示,我们称 ucontext 以及 siginfo 这一段为 Signal Frame。需要注意的是,这一部分是在用户进程的地址空间的。之后会跳转到注册过的 signal handler 中处理相应的 signal。因此,当 signal handler 执行完之后,就会执行 sigreturn 代码。
使用情况
在汇编代码中看到存在systemcall的时候可以考虑采用该方法进行尝试
下面给出我们将会用的64位函数及函数调用号和函数原型

实例:
栈迁移
原理:
劫持栈指针指向攻击者所能控制的内存处,然后再在相应的位置进行ROP。
解决了栈溢出空间大小不足的问题。
我们进入一个函数的时候,会执行call指令
1 | call func(); //push eip+4; push ebp; mov ebp ,esp |
函数执行完之后退出时执行相反操作
1 | leave ; //mov esp ,ebp pop rbp |
核心:
将栈 的 esp 和 ebp 转移到一个 输入不受长度限制的 且可控制 的 址处,通常是 bss 段地址! 在最后 ret 的时候 如果我们能够控制得 了 栈顶 esp指向的地址 就想到于 控制了 程序执行流!
32位程序-栈迁移:
题目:BUUCTF-PWN-ciscn_2019_es_2
先放着
64位程序-栈迁移:
先放着
32位shellcode的编写

64位shellcode的编写

快速生成shellcode


——————————————————————————–
泄露libc版本
- 泄露 __libc_start_main 地址
- 获取 libc 版本
- 获取 system 地址与 /bin/sh 的地址
- 再次执行源程序
- 触发栈溢出执行 system(‘/bin/sh’)
这里遇到了用puts函数和write函数来泄露libc版本的,了解了怎么使用和泄露
rop利用prinft泄露read
函数寻址
1 | https://libc.rip/#:~:text=URL%3A%20https%3A%2F%2Flibc,100 |
Libcsearcher:寻找libc的工具
puts函数泄露libc
u64(p.recvuntil(“\x7f”)
+libc.search(b”/bin/sh\x00”).next()
1 | #32位 |
1 | #32位 |
1 | #64位 |
1 | 判断libc版本32位: b"a"*offset + p32(xx@plt) + p32(ret_addr) + p32(xx@got) |
1 | #32位 |
1 | #64位 |
write函数泄露libc
1 | #32位 |
1 | #64位 |
——————————————————————————–
格式化字符串漏洞
格式化字符串漏洞函数:
以printf函数为例,它的第一个参数就是格式化字符串:“Color %s,Number %d,Float %4.2f”
然后printf函数会根据这个格式化字符串来解析对应的其它参数。

漏洞原理利用:
程序崩溃:
最简单的的攻击方法,只需要输入一串%s就可以
%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s
对于每一个 %s,printf() 都会从栈上取一个数字,把该数字视为地址,然后打印出该地址指向的内存内容,由于不可能获取的每一个数字都是地址,所以数字对应的内容可能不存在,或者这个地址是被保护的,那么便会使程序崩溃
在 Linux 中,存取无效的指针会引起进程收到 SIGSEGV 信号,从而使程序非正常终止并产生核心转储

基本的格式化字符串漏洞的格式
1 | //比如正确的写法是:printf("%s", pad) |
%c为单个字符形式
%s为多个字符形式
%d为数字形式
%f是转为浮点型
%x是转为十六进制形式,不带0x
%p是转为十六进制,但是带0x
%n 将%n之前打印出来的字符的个数存入到参数中
- 但是这里注意的是现在常用%p跟多些
一、常规题型
存在格式化字符串,满足条件之后执行shell
类似于
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
根据格式化字符串找偏移,然后正常打
1 | from pwn import* |
简单解释一下payload,前面的p32()是我们daniu(这里的题目环境是他在bss段上),因为要满足为6,所以在前面补了一个b’aa’
二、修改GOT表
主要遇到的函数
payload = fmtstr_payload(offset,{printf_got:system_plt})
32位修改GOT表
1 | from pwn import * |
64位修改GOT表
1 | from pwn import * |
这里注意到的是因为我们泄露的地址一般为6字节,但是我们接收的是8字节,一般前面还要补齐两字节的0,但是一般是不显示的。
所以我们改写只是后三个字节。分为高16字节和低16字节。
当没有system函数时,利用泄露libc基址,获得system函数地址。
1 | #32位 |
1 | from pwn import* |
三、泄露canary

格式化字符串泄露canary
首先确认我们要知道的canary的位置,距离ebp的距离然后,在gdb调试找一下偏移
之后利用漏洞泄露canary的值
然后正常ROP链构造就行
1 | from pwn import * |
后续会继续更新……………..
————————————————
中级ROP-ret2csu
——————————————————————–
整数溢出
1 | 整数溢出原理整数分为有符号和无符号两种类型,有符号数以最高位作为其符号位,即正整数最高位为1,负数为0, |
—————————————————–
关闭本地的随机化
1 | 关闭地址随机化: |
——————————————————————–
ret2syscall
1 | from pwn import * |
——————————————————————
关闭alarm函数
1 | # 将程序名为ProgrammName中的alarm替换为isnan |
——————————————————————–
mprotect函数
1 | from pwn import * |
1 | from pwn import * |
——————————————————————-
pwntools的基本函数功能的简单使用
process()函数 -打开本地文件
remote()函数 -连接远端的服务器
p32()函数 -把32位的整数打包成4个字节的二进制数据
p64()函数 -把64位的整数打包成8个字节的二进制数据
u32/u64函数 -解包字符串,得到整数。
interactive()函数 -简单来说就是与连接的主机进行交互,就是可以在命令行进行操作一样
context()函数 -配置默认的执行环境
asm(shellcraft.sh()) -使用 pwntools 库的 shellcraft 模块生成一个在 Linux 上执行 /bin/sh 的shellcode。asm 函数将这个 shellcode 汇编成机器码。
ljust(112, b’A’)函数 -ljust() 方法用来使字符串变得左对齐,并且在右边用指定的填充字符(或者空格)填充至指定的长度。
puts_plt = elf.plt[‘puts’] -PLT 是一个跳转表,用于动态链接的函数调用
puts_got = elf.got[‘puts’] -GOT 是一个表,存储了动态链接库函数的实际地址
flat()函数 -跟p32(),p64()意思是一样的
log.success()函数 -用于记录和显示成功信息。
通常是日志库(如
loguru、logging等)的一部分,用于记录成功级别的日志消息。此处我们假设使用的是某个日志库,该库有一个success方法。
readuntil()函数 -通常用于从输入流或缓冲区读取数据,直到遇到指定的分隔符。
fmtstr_payload()函数 -改函数地址的。
sendline(str(choice).encode())
1 | str(choice).encode() 将字符串编码为字节类型(默认编码为 UTF-8) |
cdll.LoadLibrary() -加载动态链接库的
发送数据:
sendline()函数 -将数据发送给连接的主机,并且换行
接收数据:
recvline()函数 -简单来说就是接受缓冲区中读取数据,直到遇到换行符为止
recvuntil()函数 -用来从进程的输出中读取数据,直到遇到指定的字节序列为止。
r.recv()函数 -用来接收数据
接收数据后,发送数据:
r.sendlineafter(delim, data) -接收数据后,在向远程连接的机器发送数据
delim:表示等待的提示符或字符串(delimiter),即在该字符串出现后再发送数据。
data:表示要发送的数据,该数据会被发送并在末尾追加一个换行符。
———————————–
ROPgadget工具的简单使用
- 首先了解一下64位汇编传参
当参数少于7个时,参数从左到右放入寄存器:rdi,rsi,rdx,rcx,r8,r9。当参数为7个以上时,与前面一样,但后面的依次从右到左放入栈中,及与32位汇编一样。
一、查找寄存器的地址
1 | ROPgadget --binary 文件名 --only "pop|ret" | grep rdi |
1 | ROPgadget --binary 文件名 --only "syscall" |
二、查找一些字符串的地址
1 | ROPgadget --binary 文件名 --string /bin/sh |
三、查看分析文件的二进制gadgets信息
1 | ROPgadget --binary 文件名 |
四、查找所有包含 int 指令
1 | ROPgadget --binary simplerop --only "int" |
查看主函数的地址
1 | objdump -d 文件名 | grep '<main>' |
显示文件 fs1 中所有的重定位条目
1 | objdump -R 文件 |
找函数地址
1 | objdump -d ./shaokao | grep syscall |
看有哪些函数可以调用的?
1 | seccomp-tools dump 文件名 |
————————————————————————
alpha3
生成仅包含 ASCII 可打印字符的 shellcode
1 | git clone https://github.com/TaQini/alpha3.git |
AE64
1 | from pwn import * |
1 | from pwn import * |
ORW
可以发现,程序禁用了 execve 和 execveat,不能直接 get shell,需要通过 ORW(open read write)来得到 flag
同时,程序也禁用了常规的 open read write,需要我们找到他们的替代品
- 对于
open,我们可以选择使用openat或者openat2(本题已禁用) - 对于
read,我们可以选择使用readv、preadv、preadv2(本题可用),pread64或者mmap(本题可用) - 对于
write,我们可以选择使用writev(本题可用),sendfile(本题可用,且能省略read)等
注意在使用 shellcraft 时需恢复 rsp 寄存器
1 | shellcode = shellcraft.openat(-100, "/flag", 0, 0) |
1 | mov rax, 0x67616c662f2e |
———————————-
one_gadget
介绍:是glibc里调用**execve(’/bin/sh’, NULL, NULL)**的一段非常有用的gadget。在我们能够控制ip(也就是pc)的时候,用one-gadget来做RCE(远程代码执行)非常方便,比如有时候我们能够做一个任意函数执行,但是做不到控制第一个参数,这样就没办法调用system(“sh”),这个时候one-gadget就可以搞定了。
使用:one-gadget 的使用非常简单,比如说希望在某个libc中找到某段启动shell的gadget,只需键入以下命令:
$ one_gadget libc-2.23.so
1 | one_gadget /path/to/libc.so.6 |
1 | one_gadget /home/llq/阿pwn/LibcSearcher/libc-database/db/libc6_2.23-0ubuntu10_amd64.so |
———————————————————
系统调用号
1 | #32位 |
1 | #64位 |
—————————————–
glibc的内存管理-(还没开始,只是看了看)
跟着画一下提纲

一、基础
linux系统在装载elf格式的程序文件时,会调用loader把可执行文件中的各个段一次载入到从某一地址开始的空间中。
用户程序可以直接使用系统调用来管理heap和mmap映射区域,但更多的时候程序都是使用C语言提供的malloc()和free()函数来动态的分配和释放内存。stack区域是唯一不需要映射,用户却可以访问的内存区域,这也是利用堆栈溢出进行攻击的基础。
进程内存布局
32位和64位的进程不一样。同样32位系统布局依赖于内核版本,也是不同,
- 栈区(Stack)— 存储程序执行期间的本地变量和函数的参数,从高地址向低地址生长
- 堆区(Heap)动态内存分配区域,通过 malloc、new、free 和 delete 等函数管理
- 未初始化变量区(BSS)— 存储未被初始化的全局变量和静态变量
- 数据区(Data)— 存储在源代码中有预定义值的全局变量和静态变量
- 代码区(Text)— 存储只读的程序执行代码,即机器指令
32位进程内存布局
在linux内核2.6.7以前,进程内存布局如下:

在该内存布局示例图中,mmap 区域与栈区域相对增长,这意味着堆只有 1GB 的虚拟地址空间可以使用,继续增长就会进入 mmap 映射区域, 这显然不是我们想要的。这是由于 32 模式地址空间限制造成的,所以内核引入了另一种虚拟地址空间的布局形式。但对于 64 位系统,因为提供了巨大的虚拟地址空间,所以64位系统就采用的这种布局方式
3.1.1.2 默认布局

64位进程内存布局

操作系统内存分配函数
heap 和mmap 映射区域是可以提供给用户程序使用的虚拟内存空间。
- 对于heap的操作,操作系统提供了brk()函数,c运行时库提供了sbrk()函数。
- 对于mmap映射区域的操作,操作系统提供了mmap()和munmap()函数。
sbrk(),brk() 或者 mmap() 都可以用来向我们的进程添加额外的虚拟内存。而glibc就是使用这些函数来向操作系统申请虚拟内存,以完成内存分配的。
这里要提到一个很重要的概念,内存的延迟分配,只有在真正访问一个地址的时候才建立这个地址的物理映射,这是 Linux 内存管理的基本思想之一。Linux 内核在用户申请内存的时候,只是给它分配了一个线性区(也就是虚拟内存),并没有分配实际物理内存;只有当用户使用这块内存的时候,内核才会分配具体的物理页面给用户,这时候才占用宝贵的物理内存。内核释放物理页面是通过释放线性区,找到其所对应的物理页面,将其全部释放的过程。W

进程的内存结构,在内核中,是用mm_struct来表示的,其定义如下:
1 | struct mm_struct { |
C语言的动态内存分配基本函数是 malloc(),在 Linux 上的实现是通过内核的 brk 系统调用。brk()是一个非常简单的系统调用, 只是简单地改变mm_struct结构的成员变量 brk 的值。

Heap操作
brk()函数为系统调用,sbrk()为c库函数。
这两个函数可以直接从堆(Heap)申请内存。
系统调用通常提过一种最小的功能,而库函数相比系统调用,提供更复杂的功能。在glibc中就是调用sbrk()函数将数据段的下界移动以来代表内存的分配和释放。sbrk函数在内核的管理下,将虚拟地址空间映射到内存,供malloc()函数使用。
函数申明如下:
1 |
|
需要说明的是,当sbrk()的参数increment为0时候,sbrk()返回的是进程当前brk值。increment 为正数时扩展 brk 值,当 increment 为负值时收缩 brk 值。
MMap操作
在linux系统中我们可以使用mmap用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。

mmap()函数将一个文件或者其他对象映射进内存。文件被映射到多个页上,如果文件上的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。
munmap 执行相反的操作,删除特定地址区域的对象映射。
函数定义如下:
1 |
|
映射关系分为:
- 文件映射:磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
- 匿名映射: 初始化全为0的内存空间。
映射关系是否共享,分为:
- 私有映射
- 多进程间数据共享,修改不反应到磁盘实际文件,是一个copy-on-write(写时复制)的映射方式。
- 共享映射
- 多进程间数据共享,修改反应到磁盘实际文件中。
整个映射关系总结起来分为:
- 私有文件映射
- 多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中
- 私有匿名映射
- mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存(malloc分配大内存会调用mmap)。例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会copy-on-write。
- 共享文件映射
- 多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件的修改会反应到实际物理文件中,也是进程间通信(IPC)的一种机制。
- 共享匿名映射
- 这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC)。
这里值得注意的是,mmap只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在mmap之后,并没有在将文件内容加载到物理页上,只有在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生”缺页”,由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
二、概述
因为每次分配,都直接使用brk(),sbrk()或者mmap()进行多次内存分配。
因此引出
内存管理
它指对计算机内存资源的分配和使用的技术。
目的:高校和快速的分配,并且在适当的时候释放和回收内存资源。
特点:

管理方式
分为:手动管理和自动管理
手动管理
指使用者在申请内存的时候使用malloc等函数进行申请,在需要释放的时候,需要调用free函数进行释放。一旦用过的内存没有释放,就会造成内存泄漏,占用更多的系统内存;如果在使用结束前释放,会导致危险的悬挂指针,其他对象指向的内存已经被系统回收或者重新使用。
简单来说就是要使用者主动申请或者释放资源。
自动管理
内存由编程语言的内存管理系统自动管理,在大多数情况下不需要使用者的参与,能够自动释放不再使用的内存。
没啥好说的。它是现代编程语言的标配,因为内存管理的模块的功能十分确定。
常见的内存管理器
1、ptmalloc
隶属于glibc的一款内存分配器,现在Linux环境上,我们使用的运行库的内存分配(malloc/new)和释放(free/delete)就是尤其提供。
2、BSD Malloc:BSD Malloc 是随 4.2 BSD 发行的实现,包含在 FreeBSD 之中,这个分配程序可以从预先确实大小的对象构成的池中分配对象。它有一些用于对象大小的size 类,这些对象的大小为 2 的若干次幂减去某一常数。所以,如果您请求给定大小的一个对象,它就简单地分配一个与之匹配的 size 类。这样就提供了一个快速的实现,但是可能会浪费内存。
3、Hoard:编写 Hoard 的目标是使内存分配在多线程环境中进行得非常快。因此,它的构造以锁的使用为中心,从而使所有进程不必等待分配内存。它可以显著地加快那些进行很多分配和回收的多线程进程的速度。
4、TCMalloc:Google 开发的内存分配器,在不少项目中都有使用,例如在 Golang 中就使用了类似的算法进行内存分配。它具有现代化内存分配器的基本特征:对抗内存碎片、在多核处理器能够 scale。据称,它的内存分配速度是 glibc2.3 中实现的 malloc的数倍。
三、glibc之内存管理(ptmalloc)
大纲如下:

1 | typedef struct _heap_info |
分配区
ptmalloc对进程内存是通过一个个Arena来进行管理的。
在ptmalloc中,分配区分为主分配区(arena)和非主分配区(narena),分配区用struct malloc_state来表示。主分配区和非主分配区的区别是 主分配区可以使用sbrk和mmap向os申请内存,而非分配区只能通过mmap向os申请内存。
当一个线程调用malloc申请内存时,该线程先查看线程私有变量中是否已经存在一个分配区。如果存在,则对该分配区加锁,加锁成功的话就用该分配区进行内存分配;失败的话则搜索环形链表找一个未加锁的分配区。如果所有分配区都已经加锁,那么malloc会开辟一个新的分配区加入环形链表并加锁,用它来分配内存。释放操作同样需要获得锁才能进行。
需要注意的是,非主分配区是通过mmap向os申请内存,一次申请64MB,一旦申请了,该分配区就不会被释放,为了避免资源浪费,ptmalloc对分配区是有个数限制的。
对于32位系统,分配区最大个数 = 2 * CPU核数 + 1
对于64位系统,分配区最大个数 = 8 * CPU核数 + 1
堆管理结构:
1 | struct malloc_state { |

需要注意几个点:
- 主分配区brk进行分配,非主分配区通过mmap进行分配
- 虽然非主分配区通过mmap进行分配,但是和大于128k直接使用mmap分配没有任何联系,大于128K的内存使用mmap分配,使用完之后直接用ummap还给系统。
- 每个线程在malloc会先获取一个area,使用area内存池分配自己的内存,这里存在竞争问题
- 如果需要在一个线程内部的各个函数调用都能访问、但其它线程不能访问的变量(被称为static memory local to a thread 线程局部静态变量),就需要新的机制来实现。这就是TLS。
- thread cache本质上是在static区为每一个thread开辟一个独有的空间,因为独有,不再有竞争。
- 每次malloc时,先去线程局部存储空间中找area,用thread cache中的area分配存在thread area中的chunk。当不够时才去找堆区的area。
chunk
ptmalloc通过malloc_chunk来管理内存,给User data前存储了一些信息,使用边界标记区分各个chunk。
定义如下:
1 | struct malloc_chunk { |
- prev_size: 如果前一个chunk是空闲的,则该域表示前一个chunk的大小,如果前一个chunk不空闲,该域无意义。
一段连续的内存被分成多个chunk,prev_size记录的就是相邻的前一个chunk的size,知道当前chunk的地址,减去prev_size便是前一个chunk的地址。prev_size主要用于相邻空闲chunk的合并。
size :当前 chunk 的大小,并且记录了当前 chunk 和前一个 chunk 的一些属性,包括前一个 chunk 是否在使用中,当前 chunk 是否是通过 mmap 获得的内存,当前 chunk 是否属于非主分配区。
fd 和 bk : 指针 fd 和 bk 只有当该 chunk 块空闲时才存在,其作用是用于将对应的空闲 chunk 块加入到空闲chunk 块链表中统一管理,如果该 chunk 块被分配给应用程序使用,那么这两个指针也就没有用(该 chunk 块已经从空闲链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费。
fd_nextsize 和 bk_nextsize: 当前的 chunk 存在于 large bins 中时, large bins 中的空闲 chunk 是按照大小排序的,但同一个大小的 chunk 可能有多个,增加了这两个字段可以加快遍历空闲 chunk ,并查找满足需要的空闲 chunk , fd_nextsize 指向下一个比当前 chunk 大小大的第一个空闲 chunk , bk_nextszie 指向前一个比当前 chunk 大小小的第一个空闲 chunk 。(同一大小的chunk可能有多块,在总体大小有序的情况下,要想找到下一个比自己大或小的chunk,需要遍历所有相同的chunk,所以才有fd_nextsize和bk_nextsize这种设计) 如果该 chunk 块被分配给应用程序使用,那么这两个指针也就没有用(该chunk 块已经从 size 链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费
如上所示,在ptmalloc中,为了节省内存,使用中的chunk和为使用的chunk在结构上是不一样的
使用的chunk:
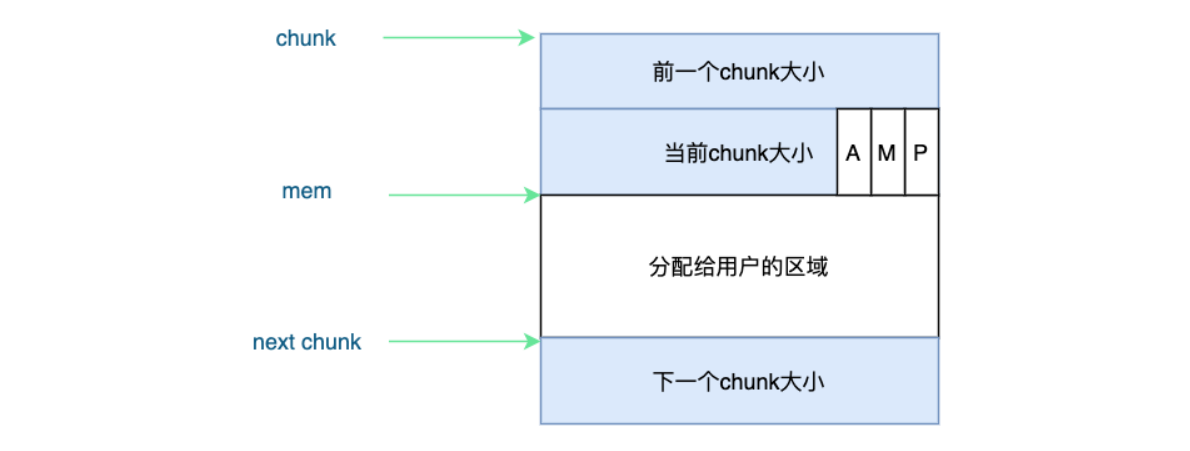
chunk指针指向chunk开始的地址
mem指针指向用户内存块开始的地址。
p=0时,表示前一个chunk为空闲,prev_size才有效
p=1时,表示前一个chunk正在使用,prev_size无效 p主要用于内存块的合并操作;ptmalloc 分配的第一个块总是将p设为1, 以防止程序引用到不存在的区域
M=1 为mmap映射区域分配;M=0为heap区域分配
A=0 为主分配区分配;A=1 为非主分配区分配。
空闲的chunk:

空闲链表(bins)
用户调用free函数释放内存的时候,ptmalloc并不会立即将其归还给系统,而是放入bins中
这样在下一次调用malloc函数申请内存的时候,就会从bins取出一块返回避免频繁调用系统调用函数,从而降低内存分配的开销。
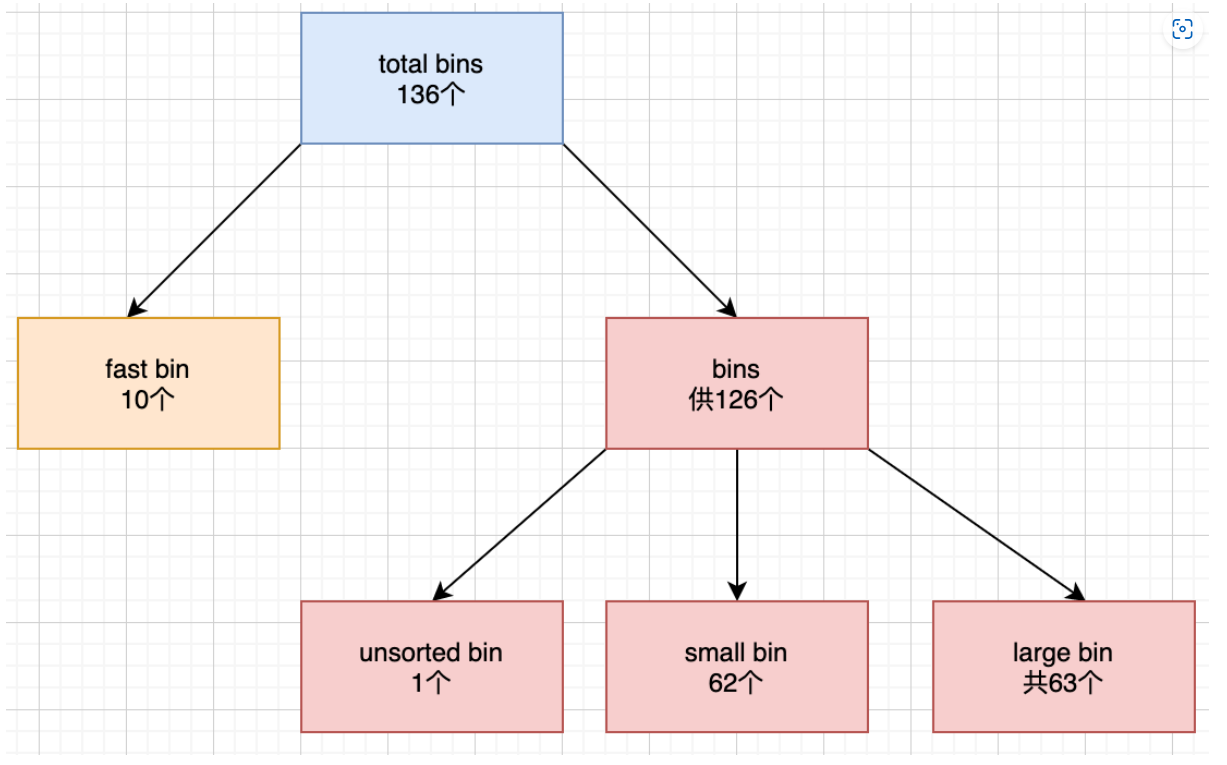
在ptmalloc中,会将大小相似的chunk链接起来,叫做bin。总共有128个bin供ptmalloc使用。
根据chunk的大小,ptmalloc将bin分为以下几种:
- fast bin
- unsorted bin
- small bin
- large bin
如图:
fast bin
申请和释放一些较小的内存空间
定义如下:
1 | mfastbinptr fastbins[NFASTBINS]; // NFASTBINS = 10 |
- 个数10
- 单链表(只用fd指针),fast bin 无论是添加还是移除chunk都是在链表尾部进行操作,操作采用后入先出的操作
- chunk size:10个fast bin中所包含的chunk size以8个字节逐渐递增,即第一个fast bin中chunk size均为16个字节,第二个fast bin的chunk size为24字节,以此类推,最后一个fast bin的chunk size为80字节。
- 不会对free chunk进行合并操作。这是因为fast bin设计的初衷就是小内存的快速分配和释放,因此系统将属于fast bin的chunk的P(未使用标志位)总是设置为1,这样即使当fast bin中有某个chunk同一个free chunk相邻的时候,系统也不会进行自动合并操作,而是保留两者。
- 在malloc查找的时候。如果申请内存大小在fast bin范围内,会优先查找,并返回。否则从其他查找。
- free操作:先通过chunksize函数根据传入的地址指针获取该指针对应的chunk的大小;然后根据这个chunk大小获取该chunk所属的fast bin,然后再将此chunk添加到该fast bin的链尾即可。

unsorted bin
unsorted bin的队列使用bins数组的第一个,是bins的一个缓冲区,加快分配速度。
当用户释放的内存大于max_fast或者fast bins合并后的chunk都会首先进入unsorted bin上。
在unsorted bin中,chunk的size 没有限制,也就是说任何大小chunk都可以放进unsorted bin中。这主要是为了让“glibc malloc机制”能够有第二次机会重新利用最近释放的chunk(第一次机会就是fast bin机制)。利用unsorted bin,可以加快内存的分配和释放操作,因为整个操作都不再需要花费额外的时间去查找合适的bin了。 用户malloc时,如果在 fast bins 中没有找到合适的 chunk,则malloc 会先在 unsorted bin 中查找合适的空闲 chunk,如果没有合适的bin,ptmalloc会将unsorted bin上的chunk放入bins上,然后到bins上查找合适的空闲chunk。
与fast bin所不同的是,unsortedbin采用的遍历顺序是FIFO(先进先出)。
结构如下:

small bin
大小小于512字节
数组从2开始编号,前62个bin为small bins,small bin每个bin之间相差8个字节,同一个small bin中的chunk具有相同大小。
每个small bin都包括一个空闲区块的双向循环链表(也称binlist)。free掉的chunk添加在链表的前端,而所需chunk则从链表后端摘除。
两个毗连的空闲chunk会被合并成一个空闲chunk。合并消除了碎片化的影响但是减慢了free的速度。
分配时,当small bin非空后,相应的bin会摘除binlist中最后一个chunk并返回给用户。
在free一个chunk的时候,检查其前或其后的chunk是否空闲,若是则合并,也即把它们从所属的链表中摘除并合并成一个新的chunk,新chunk会添加在unsorted bin链表的前端。
small bin也采用的是FIFO算法,即内存释放操作就将新释放的chunk添加到链表的front end(前端),分配操作就从链表的rear end(尾端)中获取chunk。

large bin
大于512字节的chunk
保存large chunks的bin被称为large bin,位于small bins后面。
有63个
在这63个largebins中:第一组的32个largebin链依次以64字节步长为间隔,即第一个largebin链中chunksize为1024-1087字节,第二个large bin中chunk size为1088~1151字节。第二组的16个largebin链依次以512字节步长为间隔;第三组的8个largebin链以步长4096为间隔;第四组的4个largebin链以32768字节为间隔;第五组的2个largebin链以262144字节为间隔;最后一组的largebin链中的chunk大小无限制。
bins分配如下:

特殊的chunk
top chunk,
mmaped chunk
last remainder chunk。
top trunk
堆最上面的的一段空间,它不属于任何bin,
当所有的bin都无法满足分配要求时,就要从这块区域里来分配,分配的空间返给用户,剩余部分形成新的top chunk,如果top chunk的空间也不满足用户的请求,就要使用brk或者mmap来向系统申请更多的堆空间(主分配区使用brk、sbrk,非主分配区使用mmap)。
在free chunk的时候,如果chunk size不属于fastbin的范围,就要考虑是不是和top chunk挨着,如果挨着,就要merge到top chunk中。
mmaped chunk
当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。 (chunk中的M标志位置1)
last remainder chunk
Last remainder chunk是另外一种特殊的chunk,这个特殊chunk是被维护在unsorted bin中的。
如果用户申请的size属于small bin的,但是又不能精确匹配的情况下,这时候采用最佳匹配(比如申请128字节,但是对应的bin是空,只有256字节的bin非空,这时候就要从256字节的bin上分配),这样会split chunk成两部分,一部分返给用户,另一部分形成last remainder chunk,插入到unsorted bin中。
当需要分配一个small chunk,但在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk。
last remainder chunk主要通过提高内存分配的局部性来提高连续malloc(产生大量 small chunk)的效率
chunk 切分
chunk释放时,其长度不属于fastbins的范围,则合并前后相邻的chunk。
首次分配的长度在large bin的范围,并且fast bins中有空闲chunk,则将fastbins中的chunk与相邻空闲的chunk进行合并,然后将合并后的chunk放到unsorted bin中,如果fastbin中的chunk相邻的chunk并非空闲无法合并,仍旧将该chunk放到unsorted bin中,即能合并的话就进行合并,但最终都会放到unsorted bin中。
fastbins,small bin中都没有合适的chunk,top chunk的长度也不能满足需要,则对fast bin中的chunk进行合并。
chunk 合并
前面讲了相邻的chunk可以合并成一个大的chunk,反过来,一个大的chunk也可以分裂成两个小的chunk。chunk的分裂与从top chunk中分配新的chunk是一样的。需要注意的一点是:分裂后的两个chunk其长度必须均大于chunk的最小长度(对于64位系统是32字节),即保证分裂后的两个chunk仍旧是可以被分配使用的,否则则不进行分裂,而是将整个chunk返回给用户。
四、内存分配(malloc)
调用流程图如下:

文字解释不写了就,因为懒!!
并且实际情况会复杂很多,这里也不写了!!
五、内存释放(free)
释放流程图如下:

文字略
……………………………….
2万字|30张图带你领略glibc内存管理精髓(因为OOM导致了上千万损失)_雨乐c++-CSDN博客
add
——————————————————————————
怎么样判断栈是否对齐?
在自己关心的函数设断点,运行到那时,看一下栈指针esp的情况。看是否能被16整除。
………………….
————————————————————————–
判断沙箱过滤
1 | seccomp-tools dump ./pwn |
—————————————————————————-
gdb的简单调试
run -执行一边查询
start -执行到函数的入口点
i -查看寄存器
disassemble $ -反编译
b -设置断点
distance
x -查看内存内容
x/36wx +地址
x: 这是 GDB 中的 “examine” 命令,用于查看内存内容。
/36w: 这指定了显示内存的格式和数量。
36: 表示要显示 36 个值。
w: 表示以 4 字节 (word) 为单位显示。
x: 表示以十六进制格式显示内存内容。
————————————
pwngdb的简单调试
git clone https://github.com/pwndbg/pwndbg
cd pwndbg
sudo ./setup.sh
start -开始函数
ni -继续执行
si -进入函数
disassemble 函数 -反编译
finish -完成这个函数
x/20gx $rbp -往后查看从rbp开始20个字节(64位)的内存单元。
vmmap -查看内存的基本情况
cyclic -生成随机 数组
c -继续往下执行
source (code)
p -打印指定表达式的值
Set *addr = value 给地址赋值
Set $rsp = value 给寄存器赋值
telescope 地址 -查看指定地址的内容
————————————
GCC
-fPIC -生成位置无关代码
-shared -编译器生成一个共享库(动态库),而不是一个可执行文件
————————————
C++函数
memchr函数: -用于查找指定的字符
参数说明
const void *s:指向要被搜索的内存块的指针。int c:要查找的字符,传递时会被转换为unsigned char类型。size_t n:要搜索的字节数。返回值
- 如果找到指定字符
c,则返回一个指向该字符在内存块中首次出现位置的指针。- 如果在指定的范围内未找到字符
c,则返回NULL。
strcat(dest, buf)函数 -是 C 语言标准库函数 strcat 的一个调用/
具体用来将字符串
buf连接到字符串dest的末尾
系统调用 int 80 指令
- 系统调用
在计算机中,系统调用(英语:system call),又称为系统呼叫,指运行在使用者空间的程序向操作系统内核请求需要更高权限运行的服务。 系统调用提供了用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态执行。如设备IO操作或者进程间通信。
Linux的系统调用通过int 80h实现,用系统调用号来区分入口函数。 操作系统实现系统调用的基本过程是:
应用程序调用库函数(API);
API将系统调用号存入EAX,然后通过中断调用使系统进入内核态;
内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
中断处理函数返回到API中;
API将EAX返回给应用程序。
execve函数
1 | int execve(const char *filename, char *const argv[],char *const envp[]); |
它的用法和system函数的用法是一样的。execve(/bin/sh,0,0)这样就行
——————————————————————————–
leave指令
1 | 64位 |
1 | 32位 |
暂时
简单了解gdb的使用
readelf ltrace
堆栈的利用方法
cpu架构
bss段
可读可写可执行

1 | from pwn import* |










